Data Engineering with AWS読んだ
Data Engineering with AWSという本を読みました。
どんな本か
- 2021年に出版された、AWSでのデータエンジニアリング本です
- 著者のGareth EagarさんはAWSのソリューションアーキテクトの方です
- 日本語の本だとAWSではじめるデータレイクが近い本だと思います
- こちらもAWS(JP)のソリューションアーキテクトの人が著者
この本で紹介されていること
- 収拾(Ingestion)や変換(Transformation)、利用(Consumer)などのカテゴリごとに、関連するAWSサービスの概要の説明、ハンズオンがあります
- AWS依存ではないデータエンジアリングの話もあります
紹介されているAWSサービス
(説明の大、中、小はこの本の中での相対的な量です)
紹介されているAWSサービス(Ingestion)
| サービス | 説明 | ハンズオン | 備考 | |
|---|---|---|---|---|
| DMS | 中 | 有 | ||
| MSK | 中 | Kinesisとの比較の話が主 | ||
| AppFlow | 小 | |||
| Transfer Family | 小 | |||
| Snow Family | 小 | |||
| Data Sync | 小 | |||
| Kiensis(Firehose) | 中 | 有 | ||
| Kiensis(Data Stream) | 中 | |||
| S3 | 中 | 有 |
紹介されているAWSサービス(Transform)
| サービス | 説明 | ハンズオン | 備考 | |
|---|---|---|---|---|
| Lambda | 中 | 有 | ||
| Glue | 中 | 有 |
ハンズオンは ・Data Catalog ・Crawler ・Studio |
|
| EMR | 小 |
紹介されているAWSサービス(Orchestration)
| サービス | 説明 | ハンズオン | 備考 | |
|---|---|---|---|---|
| Glue Workflow | 小 | |||
| Step Functions | 中 | 有 | ||
| Airflow(MWAA) | 小 | |||
| Data Pipeline | 小 |
紹介されているAWSサービス(Consume)
| サービス | 説明 | ハンズオン | 備考 | |
|---|---|---|---|---|
| Athena | 大 | 有 | ||
| Redshift | 大 | 有 | ||
| QuickSight | 大 | 有 | ||
|
Sagemaker Family |
中 | Family(StudioやData Wrangler)それぞれをさらっと紹介 | ||
|
Auto AI・ML系 (ComprehendやLex) |
小 |
有 (Comprehend) |
AI・ML系のサービス(Comprehend、Lex、Textract、Textract、Rekognition、Forecast、Fraud Detector、Personalize)それぞれをさらっと紹介 |
この本では(あまり)紹介されていないこと
- データエンジニアリングに特有でないAWSの知識は、知っている前提で進みます
- IAMとかVPC、EC2あたり
- タイトルにある通りAWSの本です。GCPやAzureとの比較、対応するサービスの話は一切ありません
思ったこと
- この本を取っ掛かりとして、(1)「そんなサービスもあるんだ」を片隅に入れるために使う、(2)公式ドキュメントを読む前の概要把握として使う、のが良い?気がしています
- 著者も、個別ジャンルのディープな話はしないよと記載しています(「This book was never intended as a deep dive into one specific area of data engineering」)
- 特にOrchestration(Step Functionsなど)、Ingestion(DMSやKinesisなど)は紹介している本が少ないので、この本で取っ掛かるのも良いかも
- 逆にGlueやSagemaker、EMRなどはこの本だとサラッとすぎる、かつ、専用の本があるので、そちら(もしくは公式ドキュメント)を読んだ方が良いかと
- AWSのデータサイエンス・エンジニアリングの資格(DAS、MLS)の準備としてもよさそう
- 「AWSではじめるデータレイク」との住み分けは難しいです。若干紹介サービスが違いますが、どちらか片方読めば十分なかも
Designing Cloud Data Platforms読んだ
Designing Cloud Data Platformsという本を読みました。
どんな本か
- 2021年に出版されたデータ基盤の本です
- 大企業のデータ基盤の設計(コンサル・SIer?)の人が著者です
- データ基盤を大きく6つのレイヤー(下図)に分割し、それぞれの章で説明しています
- Data Lake(②)とDatat Warehouse(⑤)を組み合わせた基盤を、この本では「Data Platform」と呼んでいるかと思います(Data Warehouse単体との対比)
- 書名に「Cloud」とついていますが一般論的な話がメインです。個別のクラウド・プロダクトの話題は軽く触れる程度です
- (Egressの通信量気をつけましょうとか、無限にスケールするオブジェクトストレージ良いよねとか)
- The Cloud Data Lakeや、 Fundamentals of Data Engineeringあたりと近いジャンルの本です
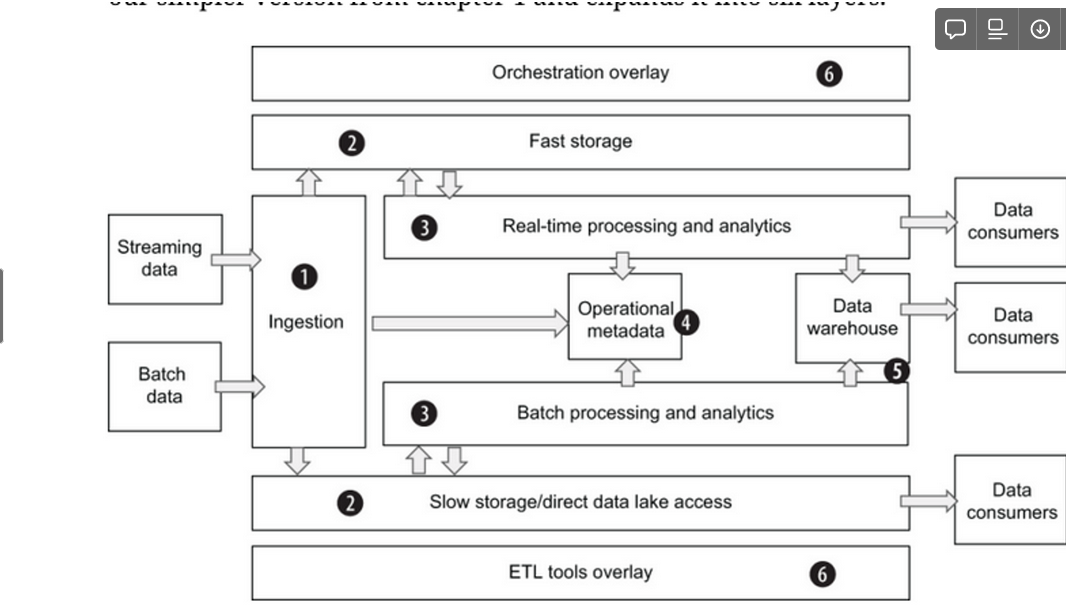
(Designing Cloud Data Platformsの3章より)
この本で紹介されていること
この本では、
が主に紹介されています。
特に、
- Schema管理
- AvroのSchema EvolutionやSchema Registryの話
- Operational Metadataの話
* パイプラインの成功失敗、処理したデータ量等のメタデータ
- Business Metadataではないことに注意
- Realtime IngestionとRealtime Processingの区別
- オブジェクトストレージのバケットの整理
あたりが、他の本であまり触れられていない、ユニークな話題だとお思います。
この本では(あまり)紹介されていないこと
- いわゆるModern Data Stack的なツール(Reverse ETLとかdbt)
- Fundamentals of Data Engineeringで触れられていた、チームやプロダクト選びの観点
- DWH・Data Lakeの先の話(BIとか機械学習)
思ったこと
The Cloud Data Lake読んだ
The Cloud Data Lakeという本を読みました。
どんな本か
- 2022/12に出版された「Cloud Data Lake 」の本です
- クラウドでのデータ基盤を紹介しています
MicrosoftでAzure StorageとかHDInsightのPMしていた、 Rukmani Gopalan さんが著者です
- (今はMSからMetaに転職している模様)
Fundamentals of Data Engineeringよりも抽象的(アーキテクチャ)な話がメインです
思ったこと
- 想定読者が難しそう。データエンジニア系の人はFundamentals of Data Engineeringの方が、より具体的でわかりやすいと思います
- アーキテクト的な人を想定しているのかしら
- 新しい概念(「Cloud Data Lake」)を提唱してそうな書名ですが、言ってる事はクラウドにData Lake・Data Warehouse作りましょうって話です
- 副題(「A Guide to Building Robust Cloud Data Architecture」)の方が、本の中身にあっている気がします
この本で紹介されていること
- データ基盤の(鳥瞰図的な)説明
- アーキテクチャの選び方
- コストとかデータガバナンスとか、非機能要件的な話
- Delta Lake・Iceberg・Hudiなどの、Table Formatの話
- この本は抽象的な話が多いですが、この話の章(Chapter 6)だけ、謎に具体的です
この本で(あまり)紹介されていないこと
今月読んだ本(2023/01)
読み終わった
booklog.jpほっとくと運用つらぽよになるので、ちゃんと文化形成・技術を使いましょうのお話。
booklog.jp大規模集団を作るようになった功罪の話。
booklog.jpボクシング等、殴るスポーツの歴史や文化のお話。タイトル買い。
ボクシング全然知らなかったので、興味深かかったです。
booklog.jpアーキテクチャパターン、特性、アーキテクトの素質やスキルのお話。
booklog.jpメインはFlaskで機械学習部分は(多分)おまけ。Blueprintとか認証、Formみたいなプラグインの話もある。
FlaskのO'Reillyの本(Flask Web Development, 2nd Edition [Book])は古い・英語なので、この本の方が読みやすいかも。
今月読んだ本(2022/12)
読み終わった
booklog.jp50年くらい前の落語協会分裂騒動の話。師匠の圓生さんへの微妙な感情と、(5代目)圓楽さん嫌いがすごい。
booklog.jpTechというよりビジネスの話。Not for me
booklog.jp下戸なので
読んでる
今月読んだ本(2022/11)
読み終わった
NNや強化学習の性能改善系の話当たり前だけどめちゃくちゃ重たい話。10年以上前に読んだ「“Give Me Your Children”: Voices from the Lodz Ghetto | Holocaust Encyclopedia」という演説をした、Chaim Rumkowskiの話が出てきて少しビックリ(他の本で名前見たことがないので)。
踏み絵の事務手続きとかの話。飛び地で行くのが面倒とか、人が集まるので出店が出たり、幕府から借りパクして怒られる藩がいたり面白い。
数少ない(唯一?)Apache Arrowの本。Arrowは、in-memoryのフォーマットを基本としつつ、色々な応用(RPCとかファイルとか)があり理解が難しいので助かります。
P-Hackingとかの話。ZANGEせよ
読んでる
今月読んだ本(2022/10)
読み終わった
booklog.jp貴重なLooker本。概要を知るには良いかも。
なんとなくGCP強化月間
booklog.jp第二版か一版をかなり前に読んだけど、記憶の更新の意味で再読。
スヴィドリガイロフ好きなので。ただ、この本の主人公はポルフィーリー?